Working with PySpark
Currently Apache Spark with its bindings PySpark and SparkR is the processing tool of choice in the Hadoop Environment. Initially only Scala and Java bindings were available for Spark, since it is implemented in Scala itself and runs on the JVM. But on the other hand, people who are deeply into data analytics often feel more comfortable with simpler languages like Python or dedicated statistical languages like R. Fortunately Spark comes out-of-the-box with high quality interfaces to both Python and R, so you can use Spark to process really huge datasets inside the programming language of your choice (that is, if Python or R is the programming language of your choice, of course).
The integration of Python with Spark allows me to mix Spark code to process huge amounts of data with other powerful Python frameworks like Numpy, Pandas and of course Matplotlib. I also know of software development teams which already know Python very well and try to avoid to learn Scala in order to focus on data processing and not on learning a new language. These teams also build complex data processing chains with PySpark.
When you are working with Python, you have two different options for development: Either use Pythons REPL (Read-Execute-Print-Loop) interface for interactive development. You could do that on the command line, but Jupyter Notebooks offer a much better experience. The other option is a more traditional (for software development) workflow, which uses an IDE and creates a complete program, which is then run. This is actually what I want to write about in this article.
PyCharm + PySpark + Anaconda = Love
Spark is a wonderful tool for working with Big Data in the Hadoop world, Python is a wonderful scripting language. So what’s missing? A wonderful IDE to work with. This is where PyCharm from the great people at JetBrains come into play. But PySpark is not a native Python program, it merely is an excellent wrapper around Spark which in turn runs on the JVM. Therefore it’s not completely trivial to get PySpark working in PyCharm – but it’s worth the effort for serious PySpark development!
So I will try to explain all required steps to get PyCharm as the (arguably) best Python IDE working with Spark as the (not-arguably) best big data processing tool in the Hadoop ecosystem. To make things a little bit more difficult, I chose to get everything installed on Windows 10 – Linux is not much different, although a little bit easier. Mac OS X – I don’t know.
So here comes the step-by-step guide for installing all required components for running PySpark in PyCharm.
- Install Anaconda Python 3.5
- Install PyCharm
- Download and install Java
- Download and install Spark
- Configure PyCharm to use Anaconda Python 3.5 and PySpark
1. Install Anaconda Python 3.5
First of all you need to install Python on your machine. I chose the Python distribution Anaconda, because it comes with high quality packages and lots of precompiled native libraries (which otherwise can be non-trivial to build on Windows). Specifically I chose to install Anaconda3, which comes with Python 3.6 (instead of Anaconda 2, which comes with version 2.7 from the previous Python mainline). Since nowadays most packages are available for Python3, I always highly recommend to prefer Python3 over Python2.
Unfortunately PySpark currently does not support Python 3.6, this will be fixed soon in a Spark 2.1.1 and 2.2.0 (see this issue). Therefore we have to create a new Python environment in Anaconda which uses Python 3.5:
1.1 Open Anaconda Navigator
Anaconda provides a graphical frontend called Anaconda Navigator for managing Python packages and Python environment. Open the application, you will be presented a screen like follows:
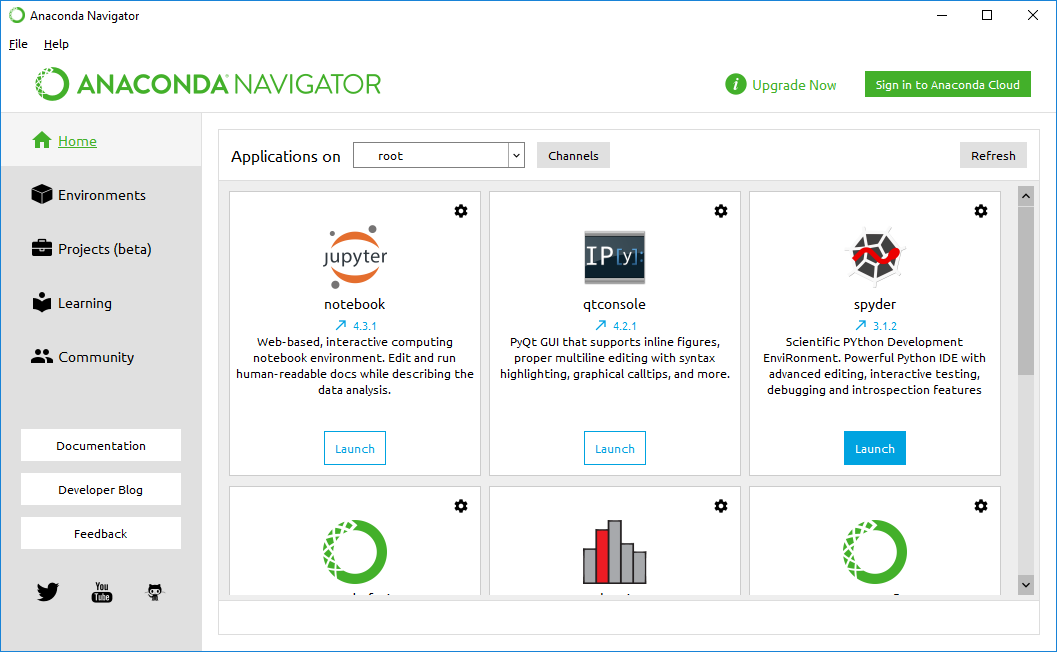
1.2 Create Python 3.5 Environment
In order to use Python 3.5 you have to create a new Python environment. Go to “environments” and then press the plus button:
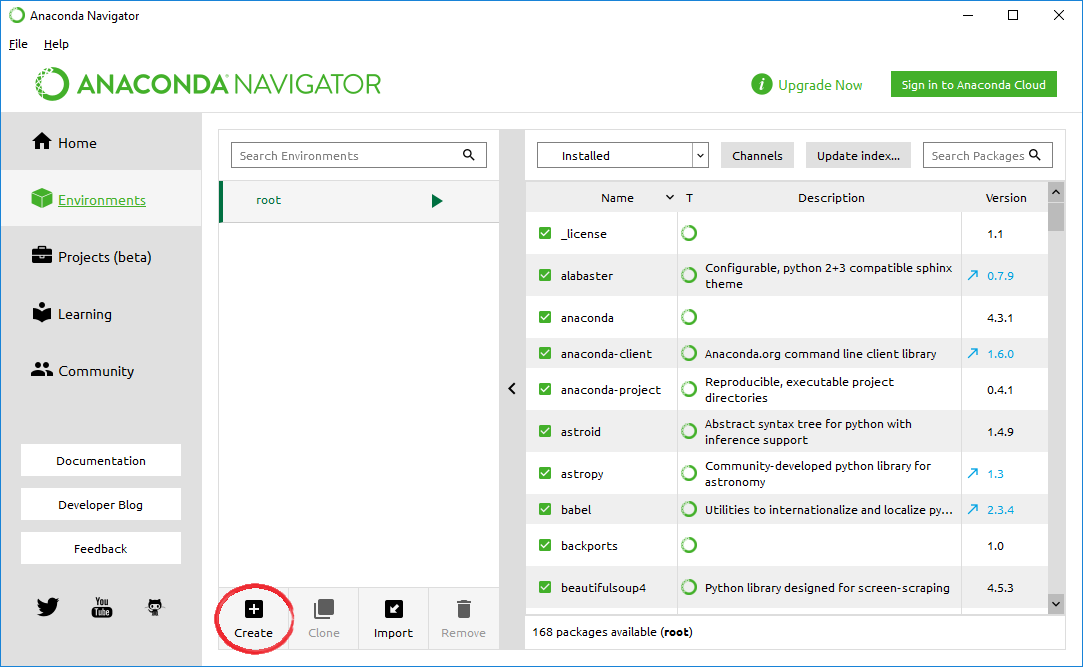
Then chose an appropriate name for the new environment (I chose “python-35”) and select the correct Python version (3.5).
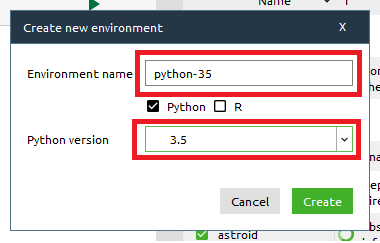
Accepting the changes will create a new Python environment and download the base components.
2. Install PyCharm
Next you can download PyCharm from JetBrains Homepage, and install it. I recommend to use the 64 bit version, but 32 bit will also work fine.
3. Download and Install Java
Since Spark itself runs in the JVM, you will also need to install Java on your machine. I chose Oracle Java, which is available for download from java.com.
4. Download and Unpack Apache Spark
Now we need to setup Apache Spark, such that it can be accessed by Python. We will use the local mode of Spark (i.e. not connecting to a cluster), this simplifies the setup. Nevertheless it will be still possible to connect to a Spark (or YARN) cluster by setting the appropriate configuration properties.
4.1 Download Apache Spark
A collection of pre-built archives is provided on the download page of the project. I chose “Spark 2.1.0 for Hadoop 2.7.0“. Note that Apache only provides “tgz” archives. These are files similar to ZIP files, and well supported on Linux and Mac, but you will need an additional program (like 7-zip for example) for unpacking these archives on Windows.
4.2 Unpack Apache Spark
After downloading the archive, you need to unpack it into an appropriate location. You do not need to unpack it into the system wide “C:\Program Files” folder, some location within your users home is sufficiant for us. I will use “C:\Users\Kaya\Projects\spark-2.1.0-bin-hadoop2.7”
5. Integrate PySpark with PyCharm
Now we have all components installed, but we need to configure PyCharm to use the correct Python version (3.5) and to include PySpark in the Python package path.
5.1 Add Python 3.5 Interpreter
After starting PyCharm and create a new project, we need to add the Anaconda Python 3.5 environment as a Python interpreter. Open “File -> Default Settings”. This will open a dialog window, where we select “Project Interpreters”, click on the small gear and select “Add Local”
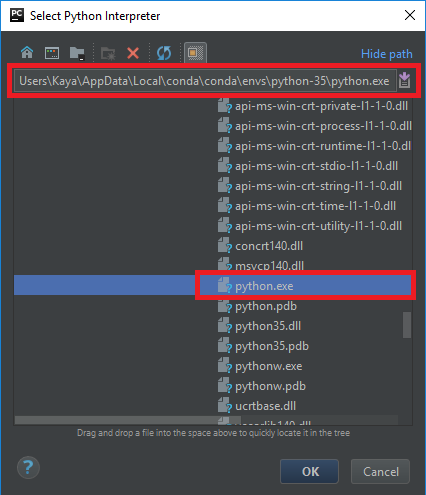
Here we select the path where the new Python environment has been created. You will find it in “%USERHOME%\AppData\Local\conda\conda\envs\<your-env-name>\python.exe”
5.2 Add Spark Libraries
Now we need to add the PySpark libraries to the Python environment. Select the newly created environment in the “Project Interpreter” section of the default settings dialog. Then click again on the small gears icon next to the interpreter name, this time select “More…”
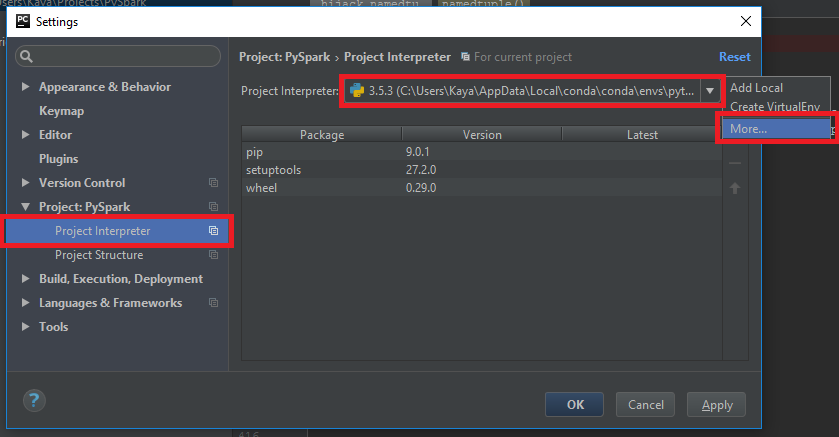
This will open a different view of all available interpreters. Press the small directory tree icon on the right, this will again open a new dialog presenting all interpreter paths:
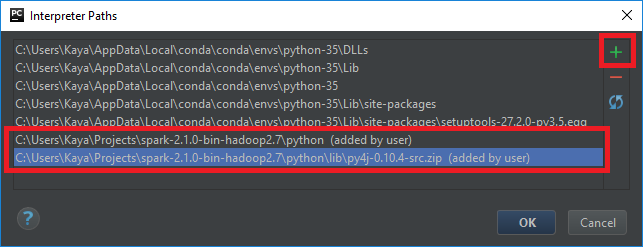
Using the “plus” icon, add two new entries for Python paths:
- %SPARK_HOME%\python
- %SPARK_HOME%\python\lib\py4j-0.10.4-src.zip
where %SPARK_HOME% denotes the directory where you have installed Spark.
5.3 Update Runtime Environment
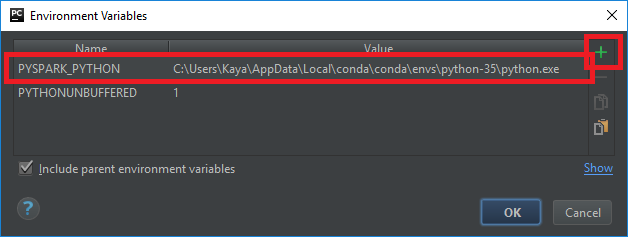
Now we are almost done, one tidbit is still missing. Internally PySpark will launch a Java process, which in turn will again launch Python worker processes. But this will fail, because the Spark Java process does not know where the correct Python version is installed. This can be configured by setting an environment variable “PYSPARK_PYTHON” in the runtime configuration. Close all dialogs, then click on the runtime icon in the top toolbar in PyCharm:

Select “Edit configurations”, which will again open a dialog window. In the “Python” panel, edit the environment variables and add a new variable “PYSPARK_PYTHON” with the location of the Python 3.5 executable file.
Calculting Pi
Now that was some work to do, it’s time to test if everything works as desired.
Although the standard example for Hadoop and related tools is to count the frequency of words in a text (“word count”), I want to use a more self-contained example, which does not need an input file. We will use a randomized algorithm for approximating the value of Pi. It’s by far not the fastest way to calculate Pi, nor is free of issues related to distributed computing and random number generation. But it’s good enogh to test if our integration works.
Python Code
from random import random
from pyspark.sql import SparkSession</code>
def create_spark_session(app_name="SparkApplication"):
spark_session = SparkSession.builder \
.appName(app_name) \
.master("local[*]") \
.getOrCreate()
spark_session.sparkContext.setLogLevel("WARN")
return spark_session
def main():
session = create_spark_session()
sc = session.sparkContext
total_points = 1000000
numbers = sc.range(0,total_points)
points = numbers.map(lambda n: (random(), random()))
circle = points.filter(lambda p: (p[0]*p[0] + p[1]*p[1]) &lt; 1)
num_inside = circle.count()
print("Pi = ", 4*num_inside/total_points)
if __name__ == '__main__':
main()


Hi Plz help me still facing this Issue:
C:UsersKishoreSJVAppDataLocalcondacondaenvspython-35python.exe C:/Users/KishoreSJV/PycharmProjects/PiCalculation/pi.py
Traceback (most recent call last):
File “C:/Users/KishoreSJV/PycharmProjects/PiCalculation/pi.py”, line 2, in
from pyspark import SparkConf, SparkContext
File “C:UsersKishoreSJVSparkspark-2.1.0-bin-hadoop2.7pythonpyspark__init__.py”, line 44, in
from pyspark.context import SparkContext
File “C:UsersKishoreSJVSparkspark-2.1.0-bin-hadoop2.7pythonpysparkcontext.py”, line 36, in
from pyspark.java_gateway import launch_gateway
File “C:UsersKishoreSJVSparkspark-2.1.0-bin-hadoop2.7pythonpysparkjava_gateway.py”, line 25, in
import platform
File “C:UsersKishoreSJVAppDataLocalcondacondaenvspython-35libplatform.py”, line 887, in
“system node release version machine processor”)
File “C:UsersKishoreSJVSparkspark-2.1.0-bin-hadoop2.7pythonpysparkserializers.py”, line 393, in namedtuple
cls = _old_namedtuple(*args, **kwargs, verbose=False, rename=False, module=None)
TypeError: namedtuple() got an unexpected keyword argument ‘module’
Process finished with exit code 1
That’s interesting, as this is just the location where the support for Python 3.6 is also broken. Maybe you have slightly different Python packages installed?
When I open an Anaconda terminal and activate the python-35 environment, I get the following information:
(python-35) C:UsersKayaAppDataLocalcondacondaenvspython-35>conda list
# packages in environment at C:UsersKayaAppDataLocalcondacondaenvspython-35:
#
pip 9.0.1 py35_1
python 3.5.3 0
setuptools 27.2.0 py35_1
vs2015_runtime 14.0.25123 0
wheel 0.29.0 py35_0
Do you also have Python 3.5.3 installed?
Another idea might be to try Spark 2.1.1 which came out just a couple of days ago. They claim that the support for Python 3.6 is also fixed.
hi i followed your procedure and i updated all.what is the problem is when i open pychar it started doing indexing.even i gave exclude folder , but it never stop takes more time. how to overcome this
Worked likes a charm ! Great stuffs thank.
However, remember to download winutils.exe and extract into d:jarshadoopbin
(https://www.google.com.vn/url?sa=t&rct=j&q=&esrc=s&source=web&cd=9&cad=rja&uact=8&ved=0ahUKEwjQm4X31pDVAhWBJJQKHeCxDpoQFghQMAg&url=https%3A%2F%2Fosdn.net%2Fprojects%2Fwin-hadoop%2Fdownloads%2F62852%2Fhadoop-winutils-2.6.0.zip%2F&usg=AFQjCNGj3eWCGMsCSP70Xf3fVQy2hjkTzw)
… and set the enviroment variable: HADOOP_HOME = PATH_OF_WINUTILS in IntelliJ described above:
https://uploads.disquscdn.com/images/27104443e91f4e602778c4733399fa5abb1ec4740d3949d4e1284e6b2b6330a0.png
Thank you very much.